빅데이터 국비 교육
[아이티윌 빅데이터 52기] Day 10 Python Basic | 리스트의 탐색
datahaseo
2025. 10. 20. 11:49
리스트의 탐색
for 문 활용
1) 리스트의 인덱스 번호를 탐색하는 방법
2) 원소 직접 탐색하는 방법
3) 둘 다 탐색하는 방법
*리스트 같은 연속성 데이터는 1씩 증가하는 인덱스 번호를 가지니, 이는 반목문 증감식의 특성과 일치하는 규칙임
#리스트의 인덱스 번호 기준으로 반복 범위 설정
for i in range(0,len(리스트)):
print(리스트[i])
#리스트 자체를 탐색하는 for 문
for i in 리스트:
print(i)
#인덱스 번호와 원소값을 모두 취득하는 반복문
for i ,v in enumerate(리스트):
print(i)
print(v)
*순서가 중요하면 상단 방법, 순서가 중요하지 않고 그 내부 값 자체가 필요하면 하단 방법
*하단 방법은 i 자체가 리스트 안의 원소가 되는 것
같은 결과여도 for 문을 다양하게 활용해 볼 수 있음

#리스트 안의 총 합과 평균을 구해보자
#리스트에 직접 접근하는 방법
height =[160,170,157,170,180]
sum=0
for i in height:
sum+=i
print('키의 총 합은',sum,'평균 키는',sum/len(height))
==================================
#몇 번쨰 순서인지 까지가 중요하다면?
height =[160,170,157,170,180]
sum=0
for i in range(0,len(height)):
sum+=height[i]
print('키의 총 합은',sum,'평균 키는',sum/len(height))
2차원 리스트를 탐색하는 패턴
2차원 리스트의 각 원소에 대한 반복문 구성
각 원소 자체가 개별적인 리스트인 경우 2차원 리스트
#같은 결과에 대한 다른 방식
1) 리스트의 인덱스 번호를 탐색하는 방법
#각 리스트의 원소 별 합계와 평균 값을 구해보자
mydata=[[88,72,83,90],[63,77,72,80]]
#우선 mydata 라는 2차원 리스트가 몇 개의 리스트를 가지고 있는지 알아보자
size=len(mydata)
print('2차원 리스트가 가진 총 리스트 수는:',size)
#2차원 리스트가 가진 길이 만큼 반복문을 실행
for row in range(0,size):
print(row,'번째 리스트',mydata[row])
size2=len(mydata[row])
#2차원 리스트의 각 리스트가 가지고 있는 원소 갯수만큼 누적 합을 더해주는 반복문 실행
sum=0
for col in range(0,size2):
sum+=mydata[row][col]
print('총합은',sum,'평균은',sum//size2)
2) 원소 직접 탐색하는 방법
#각 리스트의 원소 별 합계와 평균 값을 구해보자
#range 없이 적어보자
mydata=[[88,72,83,90],[63,77,72,80]]
#for 문에서 리스트 내 리스트를 직접 탐색하면 row 자체가 그 값이 된다
for row in mydata:
print(row)
sum=0
#2차원 리스트 내에 있는 원소를 직접 탐색한다
for col in row:
sum+=col
print('총합은',sum,'평균은',sum//len(row))
리스트 관련 함수


#len() 함수는 리스트가 가지고 있는 원소의 갯수를 길이로 출력한다
mylist=[1,2,3]
print(len(mylist))
#del() 함수는 리스트에서 인덱스로 지정한 항목을 지운다
mylist=[1,2,3]
del(mylist[1])
print(mylist)
#sorted() 함수는 리스트를 정렬하는 함수인데, 원본은 수정하지 않는 특징이 있다
mylist=[4,2,6,5,8]
asc=sorted(mylist)
print(asc)
desc=sorted(mylist,reverse=True)
print(desc)
print(mylist)
#파이썬에서 최대/최소값을 구하는 함수는 사용할 수 있지만 평균 값은 총합을 길이(갯수)로 나눠야한다
a=[1,2,3]
print(max(a))
print(min(a))
#list() 함수는 요소 내의 문자들을 하나씩 쪼개어 리스트로 만들 수 있다
a='Python'
b=list(a)
print(b)
#lsit() 함수는 튜플을 리스트로 만들어줄 수 있다
c=(1,2,3)
d=list(c)
print(d)
#range () 함수는 1씩 늘어난다
k=range(1,10)
print(type(k))
print(k)
#range() 함수는 늘어나는 범위도 지정해줄 수 있다
k=list(range(1,10,3))
print(k)
#count() 함수로 지정한 숫자의 갯수를 세어줄 수 있다
mylist=[1,2,3,2,4,2]
c=mylist.count(2)
print(c)
#index() 함수로 지정한 항목이 가장 처음 나타나는 인덱스 숫자 번호를 알 수 있다
mylist=[1,2,3,10,1,2,3,10]
x=mylist.index(10)
print(x)
#append() 함수는 뒤에서 이어 붙이는 결과를 출력한다
mylist=[1,2,3]
mylist.append(4)
print(mylist)
#append() 함수는 리스트도 더해줄 수 있다
mylist=[1,2,3]
mylist.append([5,6])
print(mylist)
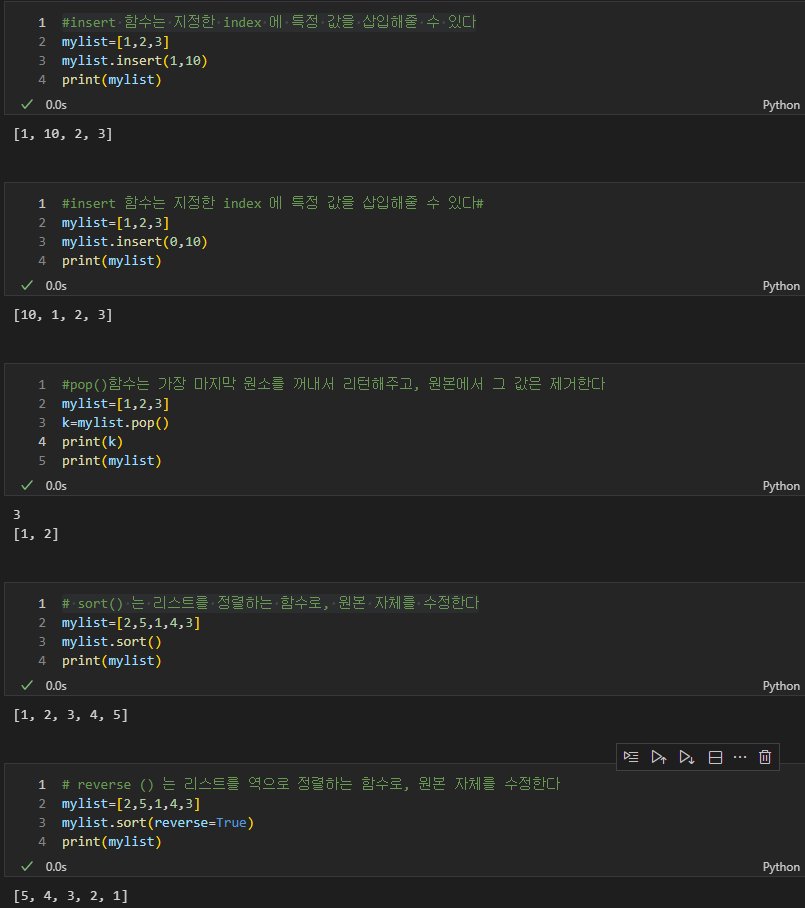
#insert 함수는 지정한 index 에 특정 값을 삽입해줄 수 있다
mylist=[1,2,3]
mylist.insert(1,10)
print(mylist)
#insert 함수는 지정한 index 에 특정 값을 삽입해줄 수 있다#
mylist=[1,2,3]
mylist.insert(0,10)
print(mylist)
#pop()함수는 가장 마지막 원소를 꺼내서 리턴해주고, 원본에서 그 값은 제거한다
mylist=[1,2,3]
k=mylist.pop()
print(k)
print(mylist)
# sort() 는 리스트를 정렬하는 함수로, 원본 자체를 수정한다
mylist=[2,5,1,4,3]
mylist.sort()
print(mylist)
# reverse () 는 리스트를 역으로 정렬하는 함수로, 원본 자체를 수정한다
mylist=[2,5,1,4,3]
mylist.sort(reverse=True)
print(mylist)
문자열의 이해

#split 을 활용하면 특정 기호를 기준으로 변수를 리스트로 만들어 구분할 수 있다
text="안녕,내,중국,이름은,뿌시야"
mylist=text.split(",")
print(mylist)
#join() 을 활용하면 특정 문자열로 원소들을 이을 수 있다
dl="&"
mylist=['안녕','내','중국','이름은','뿌시야']
text=dl.join(mylist)
print(text
#join() 을 활용하면 특정 문자열로 원소들을 이을 수 있다 *빈칸
dl=""
mylist=['안녕','내','중국','이름은','뿌시야']
text=dl.join(mylist)
print(text)
#join() 을 활용하면 특정 문자열로 원소들을 이을 수 있다 *띄어쓰기
dl=" "
mylist=['안녕','내','중국','이름은','뿌시야']
text=dl.join(mylist)
print(text)
#divmod() 를 활용하면 숫자를 나눴을 때 몫과 나머지를 출력할 수 있다
c=divmod(200,3)
print(c)
days,hours =divmod(100,3)
tpl="{0}일 {1}시간"
print(tpl.format(days,hours))
#extend() 는 append 처럼 뒤에서 이어 붙이는 효과가 있다
mylist=[1,2,3]
addon=[10,9,8,7]
mylist.extend(addon)
print(mylist)
#remove() 는 특정 원소를 삭제할 수 있다
mylist=[1,2,3,10,1,2,3,10]
mylist.remove(10)
print(mylist)문자열 포매팅


#표현은 달라도 모두 같은 결과를 보여준다
str ="나는 %d세 입니다"
print(str%20)
print("나는 %d세 입니다" %20)
age = 20
print(f"나는 {age}세 입니다")
#여러개의 포매팅을 동시에 진행할 수 있다
print("나는 %d 학년 %d반 홍찌입니다" %(4,2))
# % 뒤의 값이 %d 를 치환한다
#문자열에 대해서는 "" 가 필요하다
str ="나는 점심으로 %s 국밥을 먹었다. %d원 이었다" %("콩나물",7500)
print(str)
#틀린 코드
school_level =["초등학교","중학교","고등학교"]
graduation_year=[2014,2017,2020]
for i in school_level:
for j in graduation_year:
sentence='나는 원천%s를 %d년도에 졸업했다' %(i,j)
print(sentence)
#맞는 코드
#zip 을 이용해서 리스트 데이터의 짝을 지어줄 수 있다
school_level =["초등학교","중학교","고등학교"]
graduation_year=[2014,2017,2020]
for school,year in zip(school_level,graduation_year):
sentence='나는 원천%s를 %d년도에 졸업했다' %(school,year)
print(sentence)
# % 뒤의 값이 %d 를 치환한다
str ="나는 점심으로 %s 국밥을 먹었다. [%10d]원 이었다" %("콩나물",7500)
print(str)
# % 뒤의 값이 %d 를 치환한다
str ="나는 점심으로 %s 국밥을 먹었다. [%010d]원 이었다" %("콩나물",7500)
print(str)
#소수점 셋째자리 까지 보여주기 떄문에 넷쨰 자리에서 올린다
str1='내가 가장 좋아하는 소수는 [%0.3f]' %64.7427426
#소수점과 좌측의 빈공간을 포함해서 총 10개가 출력된다
str2='내가 가장 좋아하는 소수는 [%10.3f]' %64.7427426
#좌측의 빈 공간이 숫자 0으로 출력된다
str3='내가 가장 좋아하는 소수는 [%010.3f]' %64.7427426
print(str1)
print(str2)
print(str3)
#숫자 인덱스를 활용한 문자열 포매팅
fmt="내가 좋아하는 소동물은 {0}과(와) {1}"
rst=fmt.format('고슴도치','햄스터')
print(rst)
treat="홍찌가 좋아하는 간식은 {0},{1}"
answer=treat.format("밀웜",'해바라기씨')
print(answer)
#직접 변수를 지정해줄 수도 있따
sentence1="지금 시각은 {hour}시 {minute} 분 입니다"
time = sentence1.format(hour=16,minute=24)
print(time)
문자열 관련 함수

#내장함수 str() 파라미터로 전달된 변수를 문자열로 반환한다
#실수, boolean, 정수 등 모든 것들을 문자열로 반환할 수 있음
bool1=True
bool1_s = str(bool1)
print(type(bool1_s))
print(bool1_s)
#내장함수 str() 파라미터로 전달된 변수를 문자열로 반환한다
#실수, boolean, 정수 등 모든 것들을 문자열로 반환할 수 있음
test=15.36312
test_s = str(test)
print(type(test_s))
print(test_s)
#문자열 안에 포함된 특정 단어나 글자수 세기
#count() 메서드
message = '마지막까지 집중을 다해야만 합니다. 집중을하는 것은 어렵지만 보통 마지막에 가장 중요한 내용이 나오기 때문이죠'
print(message.count("마"))
print(message.count('집중'))
print(message.count('보통'))
#특정 글자나 단어가 처음 나타나는 위치를 조회할 때
#find() 메서드는 찾으려는 단어의 시작 위치 지점을 알려주고, 없을 경우 -1
test_message ="우리집에는 드워프 햄스터가 있는데 이름은 홍찌입니다.홍찌는 태어난지 3개월 되었어요"
print(test_message.find("홍찌"))
print(test_message.find("힝찌"))
#특정 글자나 단어가 마지막으로 나타나는 위치 조회
#rfind() 메서드는 내가 찾고자 하는 단어의 마지막 위치 시작점을 알려줌
test_message ="우리집에는 드워프 햄스터가 있는데 이름은 홍찌입니다.홍찌는 태어난지 3개월 되었어요"
print(test_message.rfind("홍찌"))
print(test_message.rfind("힝찌"))
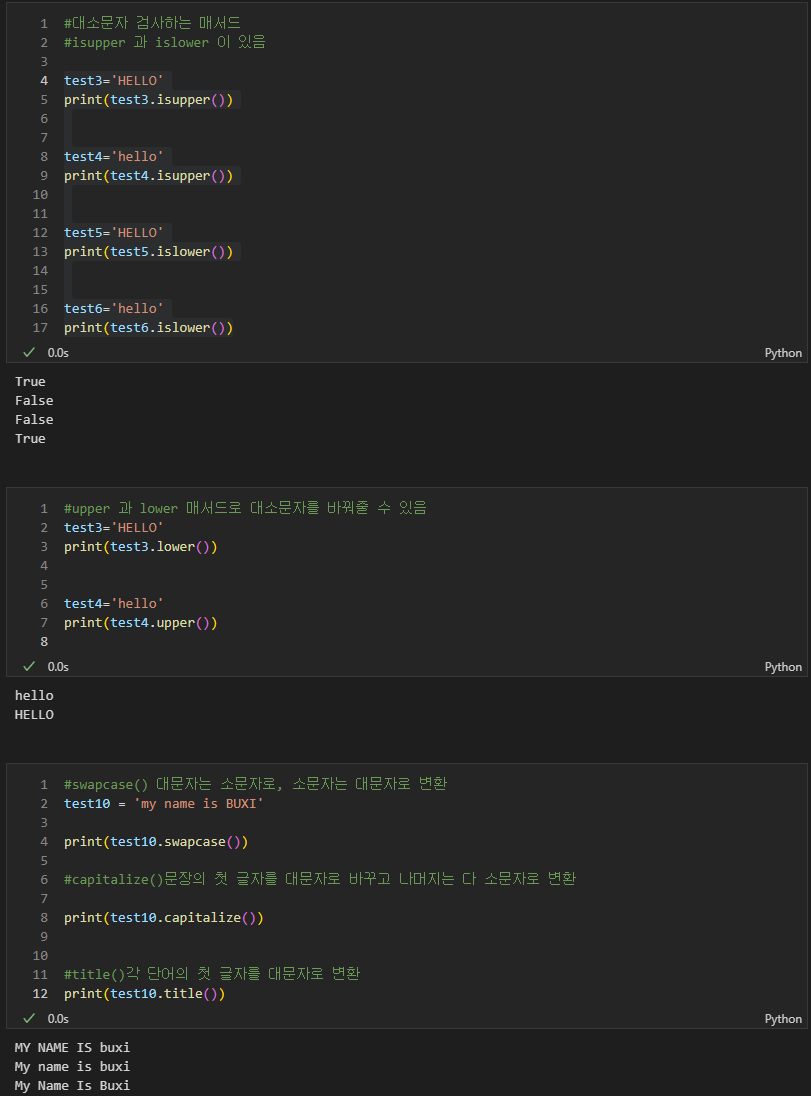
#대소문자 검사하는 매서드
#isupper 과 islower 이 있음
test3='HELLO'
print(test3.isupper())
test4='hello'
print(test4.isupper())
test5='HELLO'
print(test5.islower())
test6='hello'
print(test6.islower())
#upper 과 lower 매서드로 대소문자를 바꿔줄 수 있음
test3='HELLO'
print(test3.lower())
test4='hello'
print(test4.upper())
#swapcase() 대문자는 소문자로, 소문자는 대문자로 변환
test10 = 'my name is BUXI'
print(test10.swapcase())
#capitalize()문장의 첫 글자를 대문자로 바꾸고 나머지는 다 소문자로 변환
print(test10.capitalize())
#title()각 단어의 첫 글자를 대문자로 변환
print(test10.title())
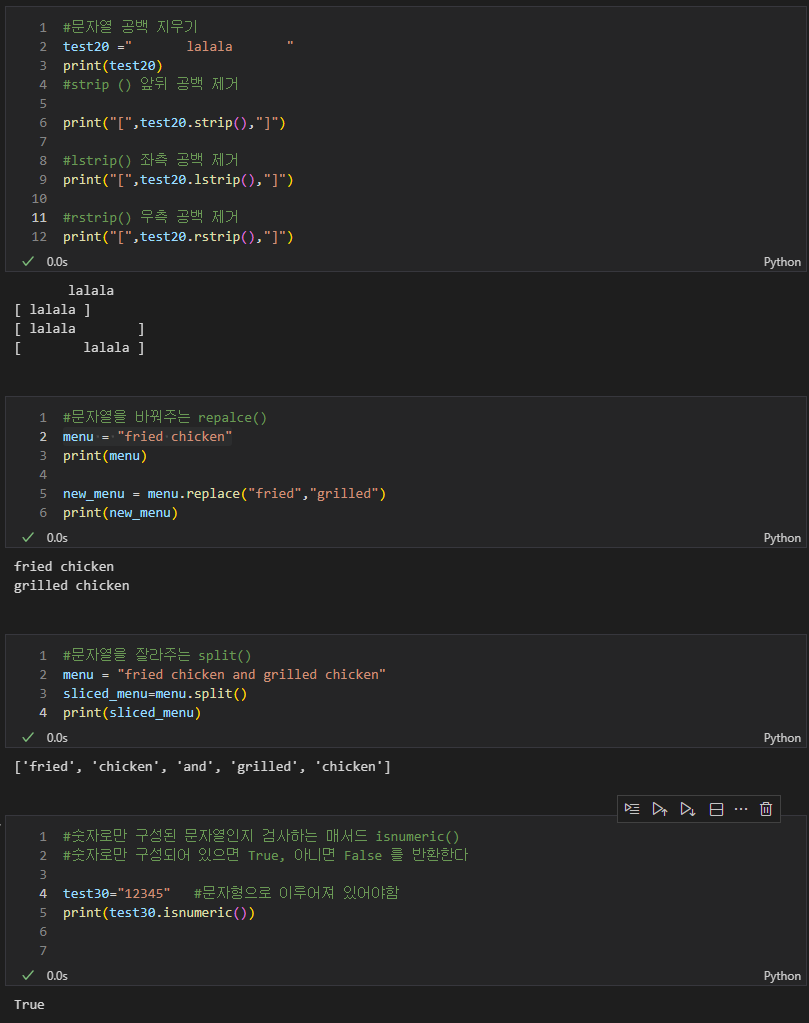
#문자열 공백 지우기
test20 =" lalala "
print(test20)
#strip () 앞뒤 공백 제거
print("[",test20.strip(),"]")
#lstrip() 좌측 공백 제거
print("[",test20.lstrip(),"]")
#rstrip() 우측 공백 제거
print("[",test20.rstrip(),"]")
#문자열을 바꿔주는 repalce()
menu = "fried chicken"
print(menu)
new_menu = menu.replace("fried","grilled")
print(new_menu)
#문자열을 잘라주는 split()
menu = "fried chicken and grilled chicken"
sliced_menu=menu.split()
print(sliced_menu)
#숫자로만 구성된 문자열인지 검사하는 매서드 isnumeric()
#숫자로만 구성되어 있으면 True, 아니면 False 를 반환한다
test30="12345" #문자형으로 이루어져 있어야함
print(test30.isnumeric())