**모든 자료의 저작권은 아이티윌 이광호 강사님
K means 개요
[1] 비지도 학습
- 종속변수 없이 컴퓨터가 데이터의 패턴/규칙을 찾아내는 방법
- 분석가의 주관 개입이 많음
- 학습이 끝난 후 평가가 어려움
[2] KMeans 클러스터링
- 각 군집의 평균을 활용하여 k 개의 클러스터로 묶는 알고리즘
- 데이터 전처리 단계에서 라벨링을 위해 사용하기도 함
[3] 기본 아이디어
- 같은 군집 내부 데이터는 서로 가깝게 위치
- 서로 다른 군집 간 데이터는 멀리 위치
- 거리 기준으로 보통 유클리드 거리 사용
[4] KMeans 의 수행 절차
1) 초기 클러스터링의 수 k 를 정의
2) k 개의 클러스터의 가상의 중심점들을 선택

3) 각 측정값을 가장 가까운 중심점의 클러스터에 할당

4) 새로운 클러스터의 중심 계산
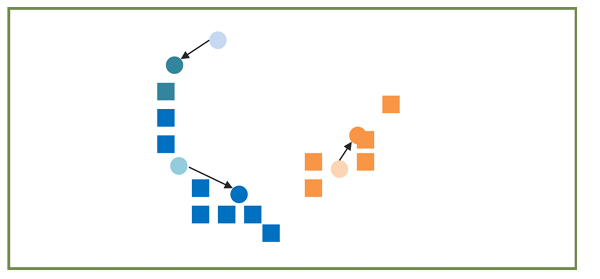
5) 클러스터 재분류 , 경계가 변경되지 않을때까지 반복하여 종료

[5] k평균 클러스터링의 특징
- 거리 기반 분류
- 유클리디안 거리의 측정
- 중심점과의 거리 최소화
- 반복 작업
- 초기에 잘못 병합된 경우를 보완함
- 여러 번 반복 수행하여 초기 오류를 회복함
- 여러 번 반복의 결과로 최적의 결과를 만들어 냄
[6] 장점
1) 짧은 계산 시간
- 간단한 알고리즘으로 계싼 시간 최소화
- 대규모 시스템에 적용 가능
2) 탐색적 방법
- 도메인 지식이 없어도 탐색 가능
- 새로운 자료에 대해 탐색을 하며 의미있는 자료를 찾아낼 수 있음
- 대용량 데이터에 대한 탐색적인 기법
3) 다양한 데이터에 적용
- 거의 모든 형태의 데이터에 대해 적용 가능
- 관찰한 데이터 간의 거리를 데이터형에 맞게만 정의하면 분석 가능
4) 분석방법의 적용이 쉬움
- 사전에 특정 변수에 대한 역할 정의가 필요하지 않음
- 관찰할 데이터 간의 거리만이 분석에 필요한 값임
[7] 단점
- 가중치와 거리 정의 필요
- 초기 클러스터링 수 결정 필요 (초기 설정값이 적합하지 않으면 결과에 영향을 줌)
- 결과 해석이 어려움
[8] 활용 에시
- EDA 데이터 탐색용
- 고객 세분화
- 지역 입지 유형 분류
[9] 실무의 주의점
- 변수 스케일 차이가 크면 반드시 표준화 필요
- K 선택시 Elbow ,Silhouette 지표 활용
- 예측 목적이나 결론을 내기보다는 구조 탐색 용도로 사용