<오늘의 TO DO>
covid19.csv 라는 파일 안에는 서울시와 전국에 대한 일별 확진자 수와 사망자 수가 있습니다.
[과제 1]
1.CSV 파일의 내용을 저장하기 위한 covid19 테이블을 myschool 데이터베이스 안에 생성하세요.
테이블 구조는 csv 파일을 참고하여 직접 정의하세요.
단, 자동 증가 형식의 기본키 컬럼은 id라는 이름으로 반드시 존재해야 합니다.
[과제 2]
년도/월별 서울시 확진자 합계, 사망자 합계, 전국 확진자 합계, 사망자 합계를 조회하는 SQL문을 Python으로 실행 후 결과를 엑셀 파일로 저장하세요.

1. myschool 데이터 베이스에 연결한 후, 해당 데이터 베이스에 CREATE 문으로 covid19.csv 파일을 밀어넣을 테이블을 생성한다
2.만들어진 비워져있는 테이블에 넣을 데이터를 준비한다 (csv 파일을 읽어와서)
3.읽어온 csv 파일을 한 행씩 insert 해준다
4.새로 데이터가 들어온 테이블에 SQLAlchemy 로 파이썬에서 sql 을 작성한다
>> 위의 순서 구체화
STEP 0. 작업하려는 파일의 구성을 확인한다
STEP 1. 마리아 DB 의 myschool 데이터 베이스에 접속한다
STEP2. 마리아 DB 에 CREATE 문으로 테이블을 생성한다
STEP 3. covid19_test.csv 파일을 r 즉 읽기 모드로 데이터를 불러온다
STEP 4 파이썬에 데이터 베이스를 연결한다
STEP 5 파이썬에 SQL INSERT 문을 작성하여, 앞서 준비한 "data" 를 하나의 행씩 밀어 넣는다
STEP 6 년도/월별 서울시 확진자와 사망자 합계를 조회하기 위한 sql 문들을 준비한다
STEP 7 파이썬에 SQL 문구를 text() 로 감싸 해당 sql을 데이터베이스에서 execute 한다.
STEP 8 pandas 에서 read sql 을 통해 데이터베이스에서 필요한 데이터를 추출하고 이를 df 객체에 넣고 to_csv 를 통해 csv 파일로 만든다
STEP 0. 작업하려는 파일의 구성을 확인한다

STEP 1. 마리아 DB 의 myschool 데이터 베이스에 접속한다

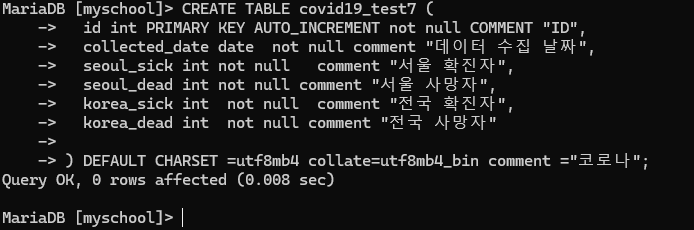
STEP2. 마리아 DB 에 CREATE 문으로 테이블을 생성한다
# 데이터 베이스 생성하기
#Query OK 확인
CREATE TABLE covid19_test7 (
id int PRIMARY KEY AUTO_INCREMENT not null COMMENT "ID",
collected_date date not null comment "데이터 수집 날짜",
seoul_sick int not null comment "서울 확진자",
seoul_dead int not null comment "서울 사망자",
korea_sick int not null comment "전국 확진자",
korea_dead int not null comment "전국 사망자"
) DEFAULT CHARSET =utf8mb4 collate=utf8mb4_bin comment ="코로나";

STEP 3. covid19_test.csv 파일을 r 즉 읽기 모드로 데이터를 불러온다
- readlines() 는 각 행을 요소로 가지는 리스트를 반환한다
- 추출된 cvs_list 를 첫 행을 건너뛰고(제목) 줄 건넘 표시를 strip() 으로 제거한 다음 콤마를 기준으로 구분해준다
- 구분된 항목들은 원하는 이름을 지정하여 딕셔너리 형태로 리스트에 넣어준다
with open ("covid19_test.csv",'r',encoding='utf-8') as f:
csv_list=f.readlines()
data=[]
for i,line in enumerate(csv_list):
if i==0:
continue
k=line.strip().split(",")
item={"collected_date":k[0],"seoul_sick":k[1],"seoul_dead":k[2],"korea_sick":k[3],"korea_dead":k[4]}
data.append(item)
data
data 리스트의 형태

STEP 4 파이썬에 데이터 베이스를 연결한다
데이터 베이스 연결 성공 문구를 확인한다
from sqlalchemy import create_engine,text
from pandas import DataFrame
import pymysql
config = {
'username' : 'root',
'password':'1234',
"hostname":'localhost',
'port':9090,
'database':'myschool',
'charset' : 'utf8mb4'
}
con_str_tpl ="mariadb+pymysql://{username}:{password}@{hostname}:{port}/{database}?charset={charset}"
con_str=con_str_tpl.format(**config)
print(con_str)
try:
#con_str 은 직전 블록에서 생성한 변수를 재사용하고 있음
engine =create_engine(con_str)
# 데이터 베이스에 접속하여 sql 실행 객체를 리턴받는다
conn=engine.connect()
print("Database connect success!!!")
except Exception as e:
#예외 발생 시 에러 메세지를 참고하여 접속 정보를 확인한다
print("Database connect fail!!!",e)
STEP 5 파이썬에 SQL INSERT 문을 작성하여, 앞서 준비한 "data" 를 하나의 행씩 밀어 넣는다
sql =text("""
INSERT INTO covid19_test7(
collected_date,seoul_sick,seoul_dead,korea_sick,korea_dead
) VALUES(:collected_date,:seoul_sick,:seoul_dead,:korea_sick,:korea_dead)
""")
affected_rows = 0
try:
for i in range(0,len(data)):
new_rows ={
"collected_date":data[i]["collected_date"] or 0,"seoul_sick":data[i]['seoul_sick'] or 0,"seoul_dead":data[i]["seoul_dead"] or 0,"korea_sick":data[i]["korea_sick"] or 0,"korea_dead":data[i]["korea_dead"] or 0
}
result=conn.execute(sql,new_rows)
affected_rows+=result.rowcount
pk_result = conn.execute(text("select last_insert_id()"))
pk = pk_result.scalar()
conn.commit()
except Exception as e:
print("SQL Error:",e)
conn.rollback()
raise SystemExit
print("저장된 행의 수: ", affected_rows)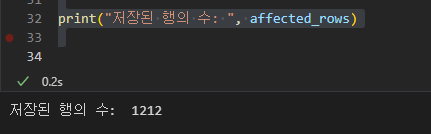

STEP 6 년도/월별 서울시 확진자와 사망자 합계를 조회하기 위한 sql 문들을 준비한다
-파이썬에서는 쿼리문에 오류에 대해서는 구체적인 에러 메세지를 반환하지 않기 때문에 이중 확인 권장
1) 연도별
select YEAR(collected_date) YEAR ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR ORDER BY YEAR
2) 월별
select MONTH(collected_date) MONTH ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY MONTH ORDER BY MONTH
3) 년도 + 월별
select DATE_FORMAT(collected_date,'%y-%m') as YEAR_MONTH_ ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR_MONTH_ ORDER BY YEAR_MONTH_
STEP 7 파이썬에 SQL 문구를 text() 로 감싸 해당 sql을 데이터베이스에서 execute 한다.
- result 객체를 생성한다 (아직 딕셔너리나 리스트 형태가 되기 전)
- 결과는 mappings() 로 감싸 딕셔너리 형태로 접근할 수 있게 되고, 이를 all() 로 전체를 리스트로 변환해준다
#년도 별
sql = text ("select YEAR(collected_date) YEAR ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR ORDER BY YEAR")
try:
result =conn.execute(sql)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
resultset=result.mappings().all()
print(resultset)
#월별
sql = text ("select MONTH(collected_date) MONTH ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY MONTH ORDER BY MONTH")
try:
result =conn.execute(sql)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
resultset=result.mappings().all()
print(resultset)
# 년도 +월별
sql = text ("select DATE_FORMAT(collected_date,'%y-%m') as YEAR_MONTH_ ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR_MONTH_ ORDER BY YEAR_MONTH_")
try:
result =conn.execute(sql)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
resultset=result.mappings().all()
print(resultset)
STEP 8 pandas 에서 read sql 을 통해 데이터베이스에서 필요한 데이터를 추출하고 이를 df 객체에 넣고 to_csv 를 통해 csv 파일로 만든다
#년도별 코로나 데이터
from pandas import read_sql
sql = text ("select YEAR(collected_date) YEAR ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR ORDER BY YEAR")
try:
df1=read_sql(sql,conn)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
df1
df1.to_csv("년도별 코로나 데이터.csv", encoding='utf-8')
#월별 코로나 데이터
from pandas import read_sql
sql = text ("select MONTH(collected_date) MONTH ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY MONTH ORDER BY MONTH")
try:
df2=read_sql(sql,conn)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
df2
df2.to_csv("월별 코로나 데이터.csv", encoding='utf-8')
#년도 + 월별 코로나 데이터
from pandas import read_sql
sql = text ("select DATE_FORMAT(collected_date,'%y-%m') as YEAR_MONTH_ ,SUM(seoul_sick) SUM_seoul_sick , SUM(seoul_dead) SUM_seoul_dead, SUM(korea_sick) SUM_korea_sick, SUM(korea_dead) SUM_korea_dead FROM covid19_test6 GROUP BY YEAR_MONTH_ ORDER BY YEAR_MONTH_")
try:
df3=read_sql(sql,conn)
except Exception as e:
print("[SQL Error]", e)
raise SystemExit
df3
df3.to_csv("년도+월 코로나 데이터.csv", encoding='utf-8')

========================================================================================
겪었던 에러1 : 행을 밀어넣는 데 1개의 행씩만 들어왔던 오류
> for 루프(반복문) 안에서 commit() 호출 시 DB에 데이터가 1개만 저장되는 오류

. 문제 현상
- for 루프를 사용해 리스트의 여러 데이터를 DB에 INSERT 하려 했음.
- try-except 구문을 사용해 예외 처리를 함.
- 루프가 중간에 중단되면, rollback()을 호출했음에도 불구하고 가장 첫 번째 데이터 1건만 DB에 저장됨.
2. 원인: 잘못된 commit() 위치 (트랜잭션 관리 실패)
commit()이 for 루프(반복문) 안에 있었던 것이 근본적인 원인이었습니다.
❌ 잘못된 코드 (오답)
try:
for item in data_list:
# 1. (데이터 1) INSERT 시도
conn.execute(sql, item)
# 2. (데이터 1) 즉시 DB에 영구 저장 (확정)
conn.commit()
# 3. (데이터 2) INSERT 시도
# 4. (데이터 2) 즉시 DB에 영구 저장 (확정)
# ...
except Exception as e:
# 5. 만약 특정 데이터(예: 3번째)에서 에러가 나면
print("에러:", e)
# 6. 롤백(취소)을 시도함
conn.rollback()
# 7. 프로그램 중단
raise SystemExit
conn.commit()이 루프 안에 있으면, 데이터 1개를 INSERT 할 때마다 즉시 '영구 저장'을 해버림
이것은 100개의 데이터를 넣는다면, 100개의 개별 트랜잭션을 만드는 것과 같습니다.
만약 3번째 데이터에서 에러가 나서 except 블록으로 이동해도, 1번째와 2번째 데이터는
이미 commit (영구 저장) 되었기 때문에 conn.rollback()으로 취소할 수 없습니다.
결국, 1번 (또는 에러 나기 직전까지) 데이터만 저장된 채로 프로그램이 멈추게 됩니다.
3. 해결: commit()을 루프 밖으로 이동 (올바른 트랜잭션)
"All or Nothing" (전부 성공 혹은 전부 실패)
데이터베이스 트랜잭션의 핵심은 모든 작업을 하나의 '묶음'으로 처리하는 것입니다.
100개를 넣으려 했다면 100개가 모두 성공해야 저장하고, 1개라도 실패하면 100개 모두를 취소해야 합니다.
이를 위해 commit()은 모든 INSERT 작업이 성공적으로 끝난 후, for 루프 밖에서 단 한 번만 호출되어야 합니다.
try:
# 1. (데이터 1~100) INSERT 시도 (아직 임시 상태)
for item in data_list:
conn.execute(sql, item)
# (루프 안에는 commit이 없음)
# 2. 모든 for 루프가 성공적으로 끝난 후,
# 지금까지의 모든 작업을 한꺼번에 영구 저장 (확정)
conn.commit()
print("모든 데이터 저장 성공!")
except Exception as e:
# 3. 만약 루프 도중(예: 3번째) 에러가 나면,
print("에러:", e)
# 4. commit()이 실행되지 않았으므로
# 지금까지 시도한 1~2번째 INSERT 작업까지 모두 취소(롤백)함.
conn.rollback()
raise SystemExit
4. 핵심 요약 (Key Takeaway)
- 트랜잭션(Transaction)은 "하나의 작업 묶음"이다.
- commit() (확정)은 try 블록의 가장 마지막, 즉 모든 작업이 성공했을 때 단 한 번만 호출해야 한다.
- rollback() (취소)은 except 블록, 즉 작업 묶음 중 하나라도 실패했을 때 호출한다.
- (오답) commit()이 반복문 안에 있으면, 그것은 더 이상 하나의 트랜잭션이 아니며 데이터 정합성이 깨진다.\
겪었던 에러2 : Incorrect integer value: '' (SQL 1366) 에러
1. 문제 현상
- 데이터를 INSERT하는 도중 try-except 블록이 실행되며 raise SystemExit로 프로그램이 중단됨.
- 에러 로그: SQL Error: (pymysql.err.DataError) (1366, "Incorrect integer value: '' for column 'seoul_sick' at row 1")
- (번역: "1번 행의 'seoul_sick' 컬럼에 잘못된 정수 값 ''이 들어왔습니다.")
2. 원인: 데이터 타입 불일치 (Type Mismatch)
데이터베이스(DB)의 컬럼 타입과 실제 INSERT하려는 값의 타입이 맞지 않았습니다.
- DB 스키마: seoul_sick 컬럼은 INTEGER (숫자) 타입으로 설정되어 있습니다.
- 입력 데이터: 원본 CSV 파일에서 값이 비어있는(blank) 셀을 읽어왔고, 이 값은 파이썬에서 **빈 문자열('')**로 처리되었습니다.
- 문제: DB는 빈 문자열('')을 숫자 0이나 NULL로 자동 변환하지 못합니다. 즉, '숫자가 아닌 값'을 '숫자 전용 칸'에 넣으려다 실패한 것입니다.
❌ 잘못된 코드 (오답)
# 원본 CSV 데이터(data[i]['seoul_sick'])에 '' (빈 문자열)이 있었음
new_rows = {
# ...
"seoul_sick": data[i]['seoul_sick'], # 이 값이 '' 였음
# ...
}
# DB는 ''를 INT로 바꿀 수 없어서 에러 발생
result = conn.execute(sql, new_rows)
3. 해결: Python에서 데이터 정제 (or 0 활용)
DB로 데이터를 보내기 전에, 파이썬 코드 단에서 먼저 비정상적인 값('')을 DB가 이해할 수 있는 값(예: 0)으로 "깨끗하게" 만들어줘야 합니다.
이때 파이썬의 or 연산자 특성을 활용했습니다.
data[i]['seoul_sick'] or 0 코드는 이렇게 동작합니다.
- data[i]['seoul_sick'] 값이 '5987' (Truthy)이면: '5987' or 0 → '5987' 반환
- data[i]['seoul_sick'] 값이 '' (Falsy)이면: '' or 0 → 0 반환
new_rows = {
"collected_date": data[i]["collected_date"],
# 값이 있으면(Truthy) 그 값을 쓰고,
# 값이 '' (Falsy)이면 0을 대신 사용
"seoul_sick": data[i]['seoul_sick'] or 0,
"seoul_dead": data[i]["seoul_dead"] or 0,
"korea_sick": data[i]["korea_sick"] or 0,
"korea_dead": data[i]["korea_dead"] or 0
}
# 이제 모든 값이 DB 타입과 일치하므로 성공
result = conn.execute(sql, new_rows)'빅데이터 국비 교육' 카테고리의 다른 글
| [아이티윌 빅데이터 52기] LAB 11 | 웹 데이터 수집하기 1 (0) | 2025.11.04 |
|---|---|
| [아이티윌 빅데이터 52기] LAB 10 | Python Basic | Flask 웹 프로그래밍 (0) | 2025.11.03 |
| [아이티윌 빅데이터 52기] LAB 09 | Python Basic | 데이터 베이스 프로그래밍 (0) | 2025.10.30 |
| [아이티윌 빅데이터 52기] Day 14 Python Basic | 메일링 리스트 (0) | 2025.10.29 |
| [아이티윌 빅데이터 52기] Day 13 Python Basic | 모듈과 라이브러리 / 파이썬 내장 라이브러리 (0) | 2025.10.29 |