[아이티윌 빅데이터 52기] LAB 11 | 웹 데이터 수집하기 1

requests 라이브러리
웹 서버와의 HTTP 토잇ㄴ을 간단하게 처리할 수 있는 라이브러리
복잡한 코드 없이 GET,POST, PUT,DELETE 요청 가능 (Thunder client test 와 동일한 기능 구현)
HTTP CLIENT 구축에 가장많이 쓰이는 REQUESTS 라이브러리

HTTP 상태코드

웹 데이터 요청하기
#라이브러리 import
import requests
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "https://data.hossam.kr/py/sample.txt" # 요청할 데이터의 url
r=session.get(url) #HTTP GET 요청
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r) # <Response [200]>
웹 서버 통신 자동으로 끊어야하니 with 구문으로 시작
웹서버에게 정상적인 브라우저인 척 하기 위해서 세션 객체를 만들어서 헤더를 바꿔준다
파이썬에선 url 도메인 외에 path 에서 오타가 나도 잘못되었다고 인식을 못하기 때문에
status 코드 확인하고,
r.reason 즉, 상태 코드를 구체적으로 받은 다음 200이 아니면 강제로 에러 발생 시키는 것
url 이 txt
http (보안 적용 x)
https (보안 적용, 오가는 모든 데이터가 암호화)
웹 데이터 요청에 대한 응답 결과 확인
#수신된 데이터의 인코딩 설정
r.encoding ="utf-8"
#수진된 결과 확인 (txt 를 읽어 r.text 를 했으므로 문자열을 가져옴)
print(r.text)
*인코딩 잘못설정해도 에러 안남, 일단 utf-8 테스트 권장
r.text 로 모든 텍스트 가져올 수있음
JSON 데이터 수집
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "https://data.hossam.kr/py/sample.json" # 요청할 데이터의 url, json 형식으로 수정
r=session.get(url) #HTTP GET 요청
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
URL 이 json
모든 json 데이터는 utf-8
#모든 JSON 데이터는 무조건 utf-8 형식을 따른다
r.encoding = "utf-8"
#JSON 형식의 응답 결과를 딕셔너리로 반환한다
my_dict = r.json()
my_dict
# 딕셔너리로 반환된 데이터는 다음과 같이 꺼내쓸 수 있다
print(my_dict["name"])r.json() 호출하면 json 데이터를 딕셔너리로 반환

2. JSON 데이터의 활용
대부분의 JSON 데이터는 표 형태의 데이터를 포함하고 있음 (딕셔너리를 포함하는 리스트)
이 부분을 출력하여 데이터 프레임 형식으로 변환하거나, 직접 반복문으로 탐색하여 데이터 분석에 활용할 수 있다
#라이브러리 불러오기
import requests
from pandas import DataFrame
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "https://data.hossam.kr/py/departments.json" # 요청할 데이터의 url
r=session.get(url) #HTTP GET 요청
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
#수신된 데이터의 인코딩 설정
r.encoding ="utf-8"
#수신된 결과를 딕셔너리로 변환
my_dict = r.json()
my_dict

#데이터 프레임으로 변환한다
df = DataFrame(my_dict["result"])
df
타이타닉 탑승객 데이터로 생존자 비율 구하기
#라이브러리 import
import requests
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "https://data.hossam.kr/py/titanic.json" # 요청할 데이터의 url
r=session.get(url) #HTTP GET 요청
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
#수신된 데이터의 인코딩 설정
r.encoding ="utf-8"
#수신된 결과를 딕셔너리로 변환
my_dict = r.json()
passengers = my_dict["passengers"]
print(passengers[:2])

#생존 비율 구하기
#리스트의 길이가 전체 탑승객의 수
total=len(passengers)
print(total)
#생존자 수 구하기
survived = 0
#생존자 명단 탐색
for i in passengers:
if i['survived'] == True:
survived +=1
#전체 비율 구하기
rate =survived*100 /total
print("전체 탑승객 %d 명 중에서 %0.2f%% 의 탑승객만 생존했다" %(total,rate))

3.파일 다운로드
바이너리 데이터에는 GET 해올 떄 STREAM =True 파라미터 추가 필요 (다운로드 모드로 바뀜)
#라이브러리 불러오기
import requests
from pandas import DataFrame
#쥬피터에서 이미지를 출력하는 모듈 불러오기
from IPython.display import Image
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "https://data.hossam.kr/py/sample.png" # 요청할 데이터의 url
r=session.get(url,stream=True) #stream=True 는 text, json, html 외에 다운로드가 필요한 형태의 데이터를 요청할 때 필요
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
-포인트
#수신된 데이터의 인코딩 설정
r.encoding ="utf-8"
#수신된 결과를 파일로 저장
with open("sample.png","wb") as f:
f.write(r.raw.read())
# 저장된 이미지 파일 출력
#수신된 결과를 딕셔너리로 변환
Image("sample.png")-포인트

4. Restful api 와의 연동
하나의 웹 url 에 여러 요청 방식으로 접속하여 웹 서버가 해당 요청 방식에 따른 기능을 수행하도록 요청할 수 있다
1) path 파라미터
2) 쿼리 스트링의 전달
두개의 다른 프로그램이 서로 통신하게 하는 것
우선 기존에 있는 파일을 명령 프롬프트에서 직접 가동한다 (켜놓고 있어야함)

해당 파이썬 파일에는 다중행/단일행 데이터 조회하는 것이 구현 되어 있음
# [1] 패키지 참조
from flask import Flask, request
from sqlalchemy import text
import datetime as dt
from mylibrary import MyDB
# [2] Flask 메인 객체 생성
app = Flask(__name__) # __name__ 은 이 소스파일의 이름
app.json.sort_keys = False # 출력 결과의 JSON 정렬 방지
# [3-1] 다중행 조회 구현
@app.route("/departments", methods=['GET'])
def get_list():
# 실행할 SQL문 정의
sql = text("SELECT id, dname, loc, phone, email FROM departments")
conn = MyDB.connect() # DB 접속
result = conn.execute(sql) # SQL문을 실행하여 결과 객체 받기
# 단일행 조회에 대한 결과 집합 추출하기
resultset = result.mappings().all()
# 반복문으로 탐색하면서 개별 레코드틀 딕셔너리로 변환해야 함
for i in range(0, len(resultset)):
resultset[i] = dict(resultset[i])
MyDB.disconnect() # DB 접속 해제 /수정 (위치 수정)
# 결과 반환하기
return {
"result": resultset,
"timestamp": dt.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
# [3-2] 단일행 조회 구현
@app.route("/departments/<id>", methods=['GET'])
def get_item(id):
# SQL문 정의
sql = text("""SELECT id, dname, loc, phone, email, established, homepage
FROM departments WHERE id=:id""")
conn = MyDB.connect() # DB 접속
result = conn.execute(sql, {"id": id}) # SQL문을 실행하여 결과 객체 받기
# 단일행 조회에 대한 결과 집합 추출하기
resultset = result.mappings().all()
MyDB.disconnect() # DB 접속 해제 (위치 수정)
return {
"result": dict(resultset[0]), # 조회 결과에 대한 딕셔너리 변환
"timestamp": dt.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
# [4] 전역 예외 처리
@app.errorhandler(Exception)
def error_handling(error):
MyDB.disconnect() # 데이터베이스 접속 해제
return {
'message': "".join(error.args),
'timestamp': dt.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}, 500
# =================================================================
# [6] Flask 웹 서버 가동
if __name__ == "__main__":
app.run(host='127.0.0.1', port=9091, debug=True)
Restful API 와의 연동
단일행 조회 구현
#HTTO Client 구현을 위한 requests 라이브러리와 pandas 라이브러리의 DataFrame 클래스를 가져온다
import requests
from pandas import DataFrame
#데이터 요청하기
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "http://127.0.0.1:9091/departments/202"
# 요청할 데이터의 url (단일행 PATH)
r=session.get(url)
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
단일행 데이터 조회하기 - 수신된 응답 결과 확인

다중행 조회 구현
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "http://127.0.0.1:9091/departments"
# 요청할 데이터의 url (다중행)
r=session.get(url)
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
다중행 데이터 응답 결과를 데이터 프레임으로 변환

<시행착오>
Flask DB 연동 오답노트
문제 1: API 요청 시 서버 응답 없음 (무한 로딩)
🔴 증상
- /departments 또는 /departments/<id>로 GET 요청 시,
- 클라이언트(브라우저, Postman)는 계속 로딩 중이고 서버는 아무 응답을 주지 않음.
- 서버 터미널에도 특별한 오류 로그가 찍히지 않음.
🔵 원인
- 데이터 인출(Fetch) 전에 DB 연결을 해제함.
- conn.execute(sql)는 쿼리 "실행 요청"일 뿐, 데이터가 파이썬으로 넘어온 상태가 아님.
- 데이터는 result.mappings().all() 또는 result.mappings().first()가 호출될 때 DB에서 실제로 인출(Fetch)됨.
- 원본 코드는 conn.execute() 직후 MyDB.disconnect()를 호출하여, 정작 데이터를 가져오려 할(all()) 땐 이미 연결이 끊겨있었음.
🟢 해결
- MyDB.disconnect()의 위치를 변경.
- result.mappings().all()처럼 데이터를 실제로 모두 가져오는 코드가 실행된 직후, 즉 return문 바로 직전에 disconnect()를 호출하도록 순서를 수정함.
💡 핵심 교훈
DB 연결은 "데이터 인출"이 완전히 끝난 후에 닫는다. execute()는 '질문하기', all()/first()는 '대답받기'다. 대답을 듣기 전에 전화를 끊지 말자!
문제 2: 클라이언트 접속 실패 (Connection Error)
🔴 증상
- 분명히 Flask 서버는 http://127.0.0.1:9091에서 정상 실행 중임.
- 그런데 Jupyter Notebook (requests 라이브러리)에서 접속 시 ConnectionError가 발생하며 200 응답을 받지 못함.
🔵 원인
- 프로토콜 불일치 (HTTP vs HTTPS)
- Flask 개발 서버는 암호화되지 않은 http://로 실행됨.
- 클라이언트 코드의 URL은 https://127.0.0.1:9091로, 암호화된 접속(https://)을 시도함.
- 서버가 https를 지원하지 않으므로 연결 자체가 거부됨.
🟢 해결
- 클라이언트(Jupyter Notebook)의 requests.get()에 사용된 URL을 https://에서 http://로 수정함.
- (수정 전) url = "https://127.0.0.1:9091/..."
- (수정 후) url = "http://127.0.0.1:9091/..."
💡 핵심 교훈
서버가 실행된 주소(프로토콜, 호스트, 포트)를 정확히 확인하자. http와 https는 완전히 다르다.

외부에서 접속 할 수 있는 PORT
FLASK 웹 서버의 데이터 추가 저장(POST) / 수정(PUT) ./ 삭제 (DELETE)
POST 방식 요청
# 저장할 데이터 구성하기
params ={
"dname":"파이썬 학과",
"loc":"IT 융합관",
"phone": "052-7788-9900",
"email" :"python@myschool.ac.kr",
"established" :2025,
"homepage":"http://python.myschool.ac.kr"
}
#데이터 저장 요청하기
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "http://127.0.0.1:9091/departments"
# 요청할 데이터의 url (다중행)
r=session.post(url,data=params)
#앞서 코드 블록에서 구성한 저장할 데이터를 담고 있는 딕셔너리를 파라미터에 넣어 post 진행
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)

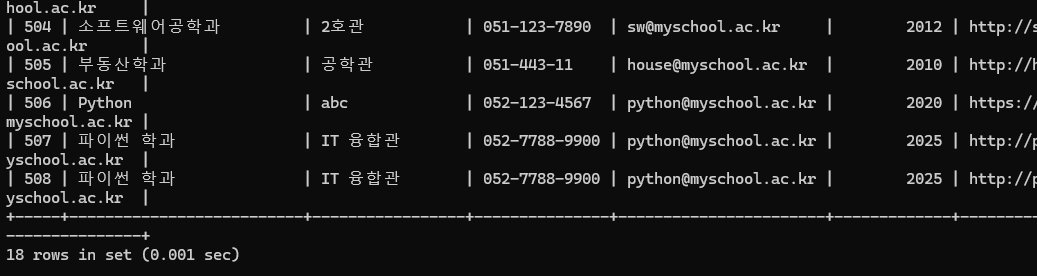
실제 DB 추가 확인 완료
PUT 방식 요청 - 데이터 수정 요청하기
# 저장할 데이터 구성하기
params ={
"dname":"파이썬짱짱 학과",
"loc":"IT 융합관",
"phone": "052-7788-9900",
"email" :"python@myschool.ac.kr",
"established" :2026,
"homepage":"http://python.myschool.ac.kr"
}
#데이터 수정 요청하기
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "http://127.0.0.1:9091/departments/%d" %new_pk
# 요청할 데이터의 url (다중행)
r=session.put(url,data=params)
#앞서 코드 블록에서 구성한 저장할 데이터를 담고 있는 딕셔너리를 파라미터에 넣어 post 진행
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)
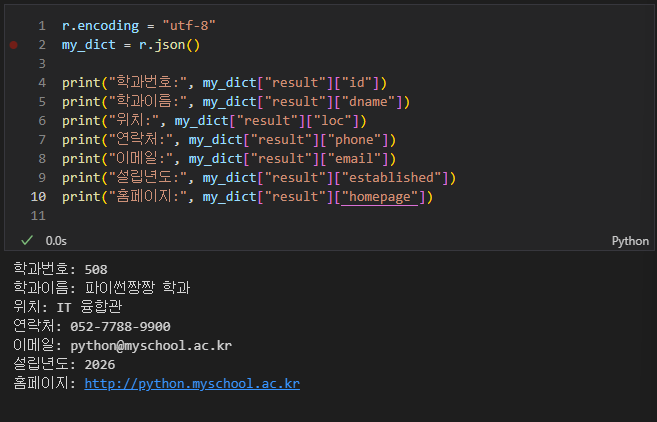

데이터 수정 확인 완료
DELETE 방식 요청 - 데이터 삭제 요청하기
# 데이터 삭제 요청하기
#세션 객체 생성
with requests.Session() as session:
#세션 객체에 웹 브라우저 정보 (UserAgent) 주입 (웹서버가 파이썬 프로그램을 정상적인 웹 브라우저로 여기도록)
session.headers.update({"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
})
url = "http://127.0.0.1:9091/departments/%d" %new_pk
# 요청할 데이터의 url (다중행)
r=session.delete(url) # 삭제는 PK 값만 PATH 파라미터로 전달한다
#앞서 코드 블록에서 구성한 저장할 데이터를 담고 있는 딕셔너리를 파라미터에 넣어 post 진행
#HTTP 상태값이 200이 아닌 경우는 강제로 에러를 발생시켜 코드의 진행을 중단시킴
if r.status_code !=200:
msg ="[%d Error] %s 에러가 발생함" % (r.status_code,r.reason)
raise Exception (msg)
print(r)

데이터 짱짱 학과 삭제 확인 완료
'빅데이터 국비 교육' 카테고리의 다른 글
| [아이티윌 빅데이터 52기] LAB 12 | 웹 데이터 수집하기 | 카카오 개발자 API | 책 검색 결과 수집 (0) | 2025.11.05 |
|---|---|
| [아이티윌 빅데이터 52기] LAB 12 | 웹 데이터 수집하기 | 영화 진흥 위원회 API | 박스 오피스 데이터 수집 (0) | 2025.11.05 |
| [아이티윌 빅데이터 52기] LAB 10 | Python Basic | Flask 웹 프로그래밍 (0) | 2025.11.03 |
| [아이티윌 빅데이터 52기] Python Basic | 데이터 베이스에 CSV 파일 넣기 | 파이썬에서 SQL 로 데이터 추출하기 (0) | 2025.10.31 |
| [아이티윌 빅데이터 52기] LAB 09 | Python Basic | 데이터 베이스 프로그래밍 (0) | 2025.10.30 |